Winning the Lottery with fastai
How to find winning tickets in your neural network
Creating sparse neural networks is a very hot topic at the moment. It is believed to make them smaller, faster and with better generalization capabilities1. For a long time however, it was believed that sparse networks were difficult to train. The traditional way of getting them was therefore to first train a dense network to convergence, then prune it to make it sparse, eventually fine-tuning it a tiny bit more to recover performance. However, some recent research has shown that not only it was possible to train sparse networks, but also that they may outperform their more-parameterized, dense, counterpart. The paper that initiated this trend talks about "lottery tickets", that may be hidden in neural networks2. In this blog post, we are going to explain what they are and how we can find them, with the help of fastai, and more particularly fasterai, a library to create smaller and faster neural networks that we created.
Let's first introduce what The Lottery Ticket Hypothesis is for those who may have never heard about it. It is a fascinating characteristic of neural networks that has been discovered by Frankle and Carbin in 20192. The gist of this hypothesis can be phrased as the following:
In a neural network, there exists a subnetwork that can be trained to at least the same accuracy and in at most the same training time as the whole network. The only condition being that both this sub- and the complete networks start from the same initial conditions.
This subnetwork, called the "winning ticket" (as it is believed to have won at the initialization lottery), can be found by using pruning on the network, removing useless connections.
The steps to unveil this winning ticket are:
- Get a freshly initialized network, possessing a set of weights $W_0$.
- Train it for a certain amount $T$ of iterations, giving us the network with weights $W_T$.
- Prune a portion of the smallest weights, i.e. the weights that possess the lowest $l_1$-norm, giving us the network with weights $W_T \odot m$, with $m$ being a binary mask constituted of $0$ for weights we want to remove and $1$ for those we want to keep.
- Reinitialize the remaining weights to their original value, i.e. their value at step 1), giving us the network with weights $W_0 \odot m$.
- Stop if target sparsity is reached or go back to step 2).
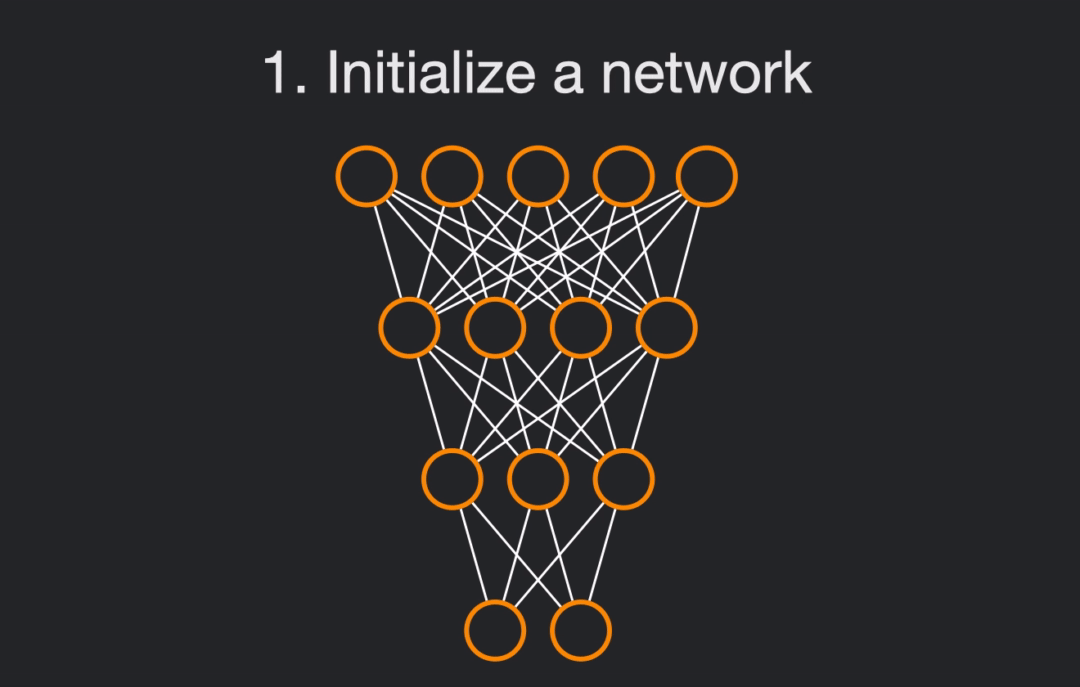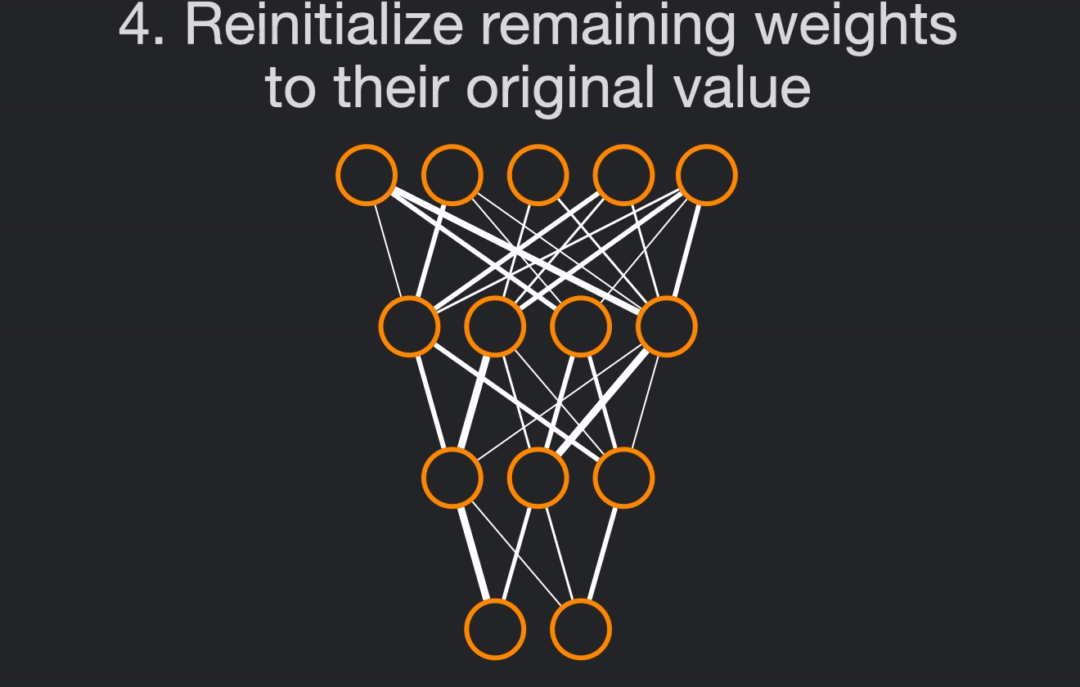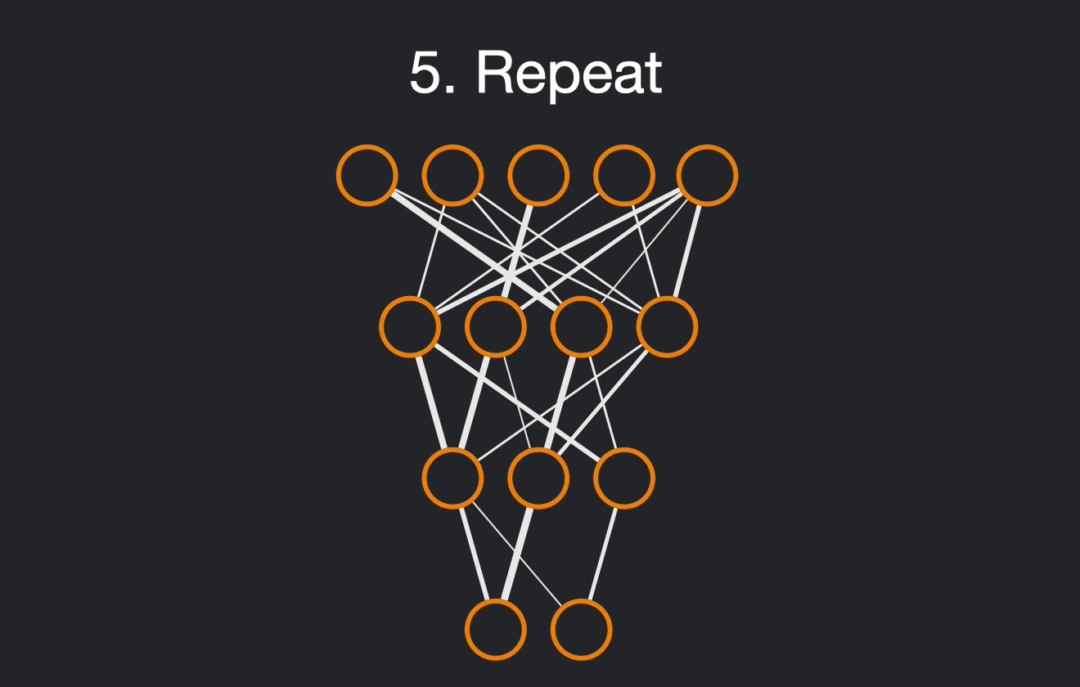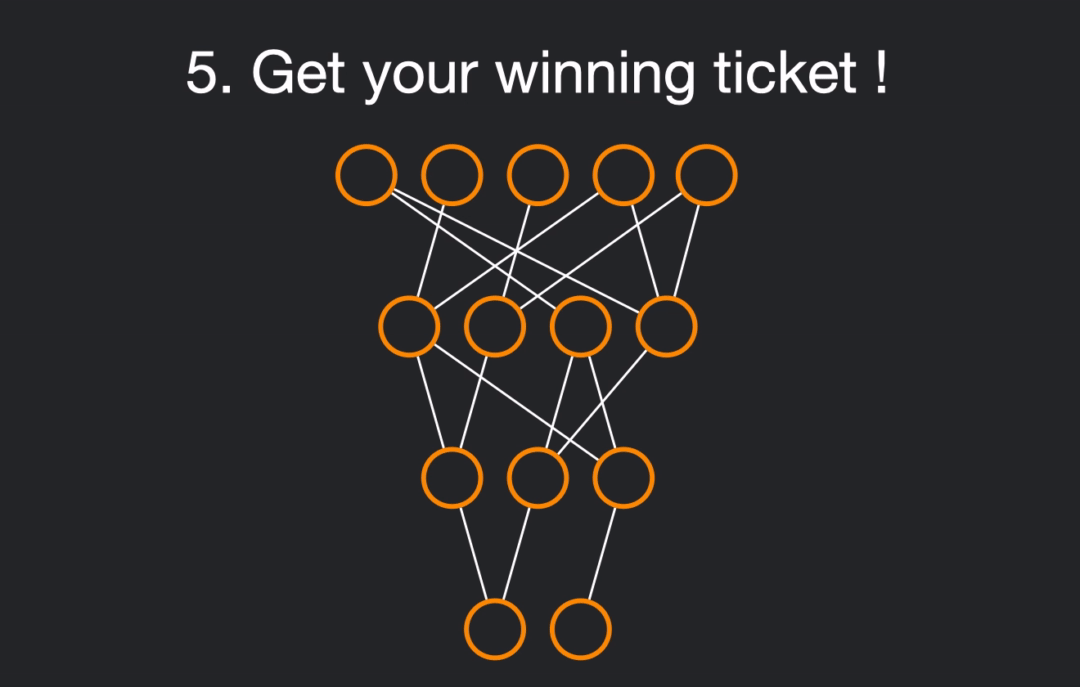
We will conduct this tutorial by using a ResNet-18 architecture, trained on Imagenette, a subpart of Imagenet using only 10 classes.
We first want a baseline of the complete model that we can then compare to.
learn = Learner(dls, resnet18(num_classes=10), metrics=accuracy)
Let's save the weights of this model, so that we can be sure to start from the exact same network in our further experiments.
initial_weights = deepcopy(learn.model.state_dict())
As this is our baseline, it will not be pruned. Thus, this model corresponds to $W_T$, with $T$ chosen to be $5$ epochs. So let's train it and report the final accuracy.
learn.fit(5)
After training, our baseline network is $68\%$ accurate at discriminating between the 10 classes of our validation set.
Can we please find winning tickets now ?
We have already shown in a previous blog post how to prune a network with fasterai. As a quick reminder, this can be done by using the SparsifyCallback callback during training.
The only things to specify in the callback are:
-
end_sparsity, the target final level of sparsity in the network -
granularity, the shape of parameters to remove, e.g.weightorfilter -
method, either prune the weights in each layer separately (local) or in the whole network (global) -
criteria, i.e. how to score the importance of parameters to remove -
schedule, i.e. when pruning is applied during training
In the original paper, authors discover tickets using an Iterative Magnitude Pruning (IMP), meaning that the pruning is performed iteratively, with a criteria based on magnitude, i.e. the $l_1$-norm of weights. Authors also specify that they remove individual weights, comparing them across the network globally.
Luckily for us, all of these were already available in fasterai! We now know most of the parameters of our callback:
SparsifyCallback(end_sparsity, granularity='weight', method='global', criteria=large_final, schedule=iterative)
We are all set then ! Well almost... If you remember correctly the 5 steps presented earlier, we need to keep track of the set of weights $W_0$, at initialization. We also need to reset our weights to their initial value after each pruning step.
In fasterai this can be done by:
- passing the
lthargument toTrue. Behind the hood, fasterai will save the initial weights of the model and reset them after each pruning step - Optionnally setting a
start_epoch, which affects at which epoch the pruning process will start.
Let's recreate the exact same model as the one we used for baseline.
learn = Learner(dls, resnet18(num_classes=10), metrics=accuracy)
learn.model.load_state_dict(initial_weights)
In fasterai, the iterative schedule has 3 steps by default, which can easily be changed but we'll stick with it for our experiments.
We'll thus have 3 rounds of pruning, and that our network will therefor be reset 3 times. As we want the network to be trained for $T=5$ epochs at each round, this means that the total epochs over which pruning will occur is $3 \times 5 = 15$ epochs.
But before performing any round of pruning, there is first a pretraining phase of $T$ epochs. The total number of epochs is then $20$.
Let's train this bad boy and see what happens !
sp_cb = SparsifyCallback(50, 'weight', 'global', large_final, iterative, start_epoch=5, lth=True)
learn.fit(20, cbs=sp_cb)
As can be seen from the verbose below training results, the weights are reset to their original value every 5 epochs. This can also be observed when looking at the accuracy, which drops after each pruning round.
After each round, the sparsity level is increased, meaning that the binary mask $m$ in $W_T \odot m$ has more and more zeroes as the training goes.
The last round, performed at a constant sparsity level of $50\%$, is able to reach $72\%$ of accuracy in 5 epochs, which is better than our baseline !
However, authors noticed that this IMP procedure may fail on deeper networks3, they thus propose to weaken the original Lottery Ticket Hypothesis, making the network to be reset to weights early in training instead of at initialization, i.e. our step 4) now resets the weights to $W_t \odot m$ with $t<T$. Such a subnetwork is no longer called a "winning" ticket, but a "matching" ticket. In this case, the regular LTH is just the particular case of $t=0$.
In fasterai, this can be done by changing the rewind_epoch value to the epoch you want your weights to be reset to, everything else stays the same. Let's try this !
learn = Learner(dls, resnet18(num_classes=10), metrics=accuracy)
learn.model.load_state_dict(initial_weights)
sp_cb = SparsifyCallback(50, 'weight', 'global', large_final, iterative, start_epoch=5, lth=True, rewind_epoch=1)
learn.fit(20, cbs=sp_cb)
We can see here the benefits of rewinding, as the network has reached $75\%$ in $5$ epochs, which is better than plain LTH, but also way better than the original, dense model.
Remark: The current methods return the winning ticket after it has been trained, i.e. $W_T \odot m$ . If you would like to return the ticket re-initialized to its rewind epoch, i.e. the network $W_t \odot m$, just pass the argument
reset_end=Trueto the callback.
It thus seem to be possible to train sparse networks, and that they even are able to overperform their dense counterpart ! I hope that this blog post gave you a better overview of what Lottery Tickets are and that you are now able to use this secret weapon in your projects. Go win yourself the initialization lottery ! 🎰
If you notice any mistake or improvement that can be done, please contact me ! If you found that post useful, please consider citing it as:
@article{hubens2020fasterai,
title = "Winning the Lottery with fastai",
author = "Hubens, Nathan",
journal = "nathanhubens.github.io",
year = "2022",
url = "https://nathanhubens.github.io/posts/deep%20learning/2022/02/16/Lottery.html"
}