size, bs = 128, 32
dls = get_dls(size, bs)Walkthrough
Walkthrough
Let’s start with a bit of context for the purpose of the demonstration. Imagine that we want to deploy a VGG16 model on a mobile device that has limited storage capacity and that our task requires our model to run sufficiently fast. It is known that parameters and speed efficiency are not the strong points of VGG16 but let’s see what we can do with it.
Let’s first check the number of parameters and the inference time of VGG16.
learn = Learner(dls, models.vgg16_bn(num_classes=10), metrics=[accuracy])num_parameters = get_num_parameters(learn.model)
disk_size = get_model_size(learn.model)
print(f"Model Size: {disk_size / 1e6:.2f} MB (disk), {num_parameters} parameters")Model Size: 537.30 MB (disk), 134309962 parametersSo our model has 134 millions parameters and needs 537MB of disk space in order to be stored
model = learn.model.eval().to('cpu')
x,y = dls.one_batch()print(f'Inference Speed: {evaluate_cpu_speed(learn.model, x[0][None])[0]:.2f}ms')Inference Speed: 26.33msAnd it takes 26ms to perform inference on a single image.
Snap ! This is more than we can afford for deployment, ideally we would like our model to take only half of that…but should we give up ? Nope, there are actually a lot of techniques that we can use to help reducing the size and improve the speed of our models! Let’s see how to apply them with FasterAI.
We will first train our VGG16 model to have a baseline of what performance we should expect from it.
learn.fit_one_cycle(10, 1e-4)| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 2.118902 | 1.796707 | 0.382930 | 00:24 |
| 1 | 1.697520 | 1.757372 | 0.452484 | 00:24 |
| 2 | 1.365785 | 1.360465 | 0.575287 | 00:24 |
| 3 | 1.244159 | 1.231451 | 0.584459 | 00:24 |
| 4 | 1.072958 | 1.381251 | 0.578599 | 00:24 |
| 5 | 0.977561 | 0.853106 | 0.730446 | 00:24 |
| 6 | 0.800931 | 0.774717 | 0.750573 | 00:24 |
| 7 | 0.690902 | 0.650088 | 0.796433 | 00:24 |
| 8 | 0.614583 | 0.613500 | 0.801019 | 00:24 |
| 9 | 0.600255 | 0.599785 | 0.808408 | 00:24 |
So we would like our network to have comparable accuracy but fewer parameters and running faster… And the first technique that we will show how to use is called Knowledge Distillation
Knowledge Distillation
Knowledge distillation is a simple yet very efficient way to train a model. It was introduced in 2006 by Caruana et al.. The main idea behind is to use a small model (called the student) to approximate the function learned by a larger and high-performing model (called the teacher). This can be done by using the large model to pseudo-label the data. This idea has been used very recently to break the state-of-the-art accuracy on ImageNet.
When we train our model for classification, we usually use a softmax as last layer. This softmax has the particularity to squish low value logits towards 0, and the highest logit towards 1. This has for effect to completely lose all the inter-class information, or what is sometimes called the dark knowledge. This is the information that is valuable and that we want to transfer from the teacher to the student.
To do so, we still use a regular classification loss but at the same time, we’ll use another loss, computed between the softened logits of the teacher (our soft labels) and the softened logits of the student (our soft predictions). Those soft values are obtained when you use a soft-softmax, that avoids squishing the values at its output. Our implementation follows this paper and the basic principle of training is represented in the figure below:
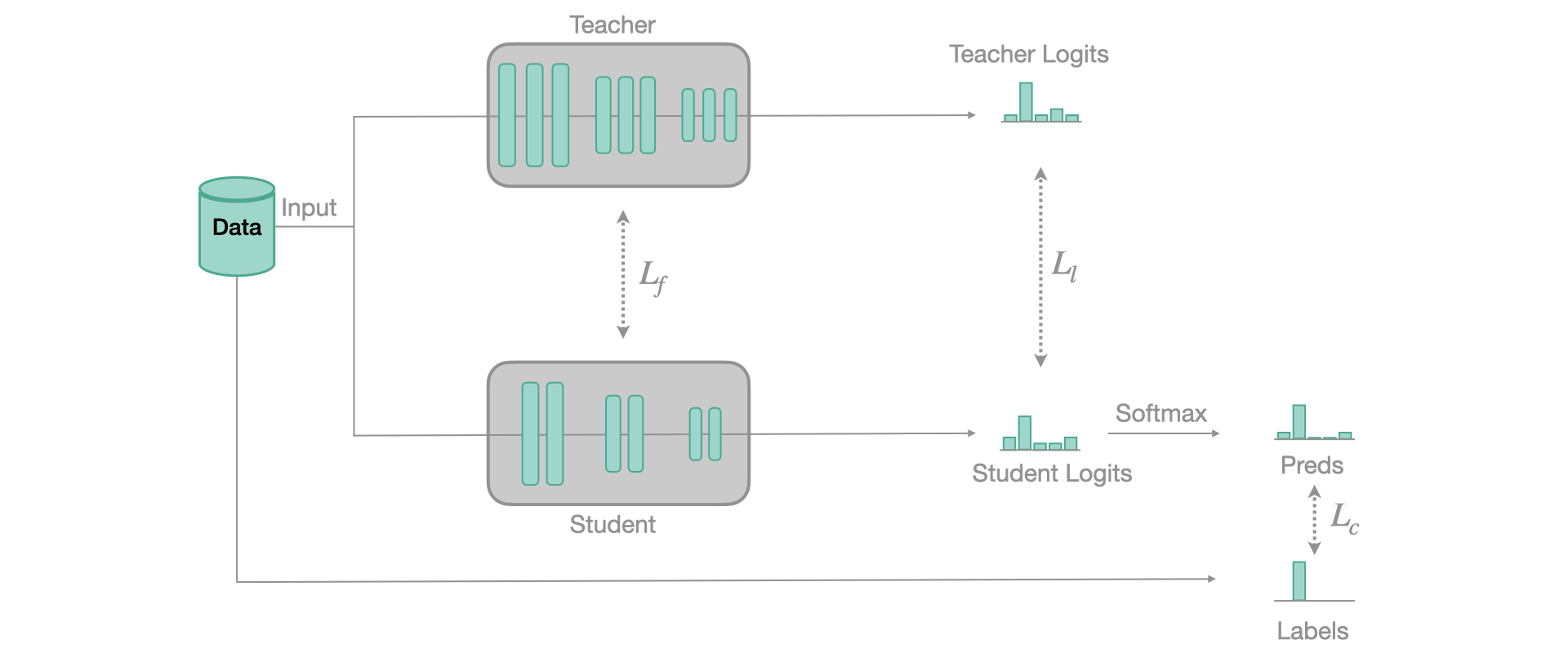
To use Knowledge Distillation with FasterAI, you only need to use this callback when training your student model:
KnowledgeDistillation(teacher.model, loss)You only need to give to the callback function your teacher learner. Behind the scenes, FasterAI will take care of making your model train using knowledge distillation.
from fasterai.distill.all import *The first thing to do is to find a teacher, which can be any model, that preferrably performs well. We will chose VGG19 for our demonstration. To make sure it performs better than our VGG16 model, let’s start from a pretrained version.
teacher = vision_learner(dls, models.vgg19_bn, metrics=[accuracy])
teacher.fit_one_cycle(3, 1e-4)| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.921188 | 0.367872 | 0.891210 | 00:16 |
| 1 | 0.449437 | 0.222757 | 0.928153 | 00:16 |
| 2 | 0.426467 | 0.205059 | 0.935796 | 00:16 |
Our teacher has 94% of accuracy which is pretty good, it is ready to take a student under its wing. So let’s create our student model and train it with the Knowledge Distillation callback:
student = Learner(dls, models.vgg16_bn(num_classes=10), metrics=[accuracy])
kd_cb = KnowledgeDistillationCallback(teacher.model, SoftTarget)
student.fit_one_cycle(10, 1e-4, cbs=kd_cb)| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 5.904119 | 5.542538 | 0.427006 | 00:38 |
| 1 | 4.528544 | 4.491541 | 0.508790 | 00:38 |
| 2 | 3.670337 | 4.807127 | 0.497834 | 00:38 |
| 3 | 3.159431 | 3.037996 | 0.663694 | 00:38 |
| 4 | 2.864913 | 2.860051 | 0.704459 | 00:38 |
| 5 | 2.388322 | 2.319992 | 0.742420 | 00:38 |
| 6 | 2.054017 | 2.105503 | 0.774267 | 00:38 |
| 7 | 1.790077 | 1.804504 | 0.792611 | 00:38 |
| 8 | 1.707000 | 1.659822 | 0.810955 | 00:38 |
| 9 | 1.620380 | 1.658448 | 0.810446 | 00:38 |
And we can see that indeed, the knowledge of the teacher was useful for the student, as it is clearly overperforming the vanilla VGG16.
Ok, so now we are able to get more from a given model which is kind of cool ! With some experimentations we could come up with a model smaller than VGG16 but able to reach the same performance as our baseline! You can try to find it by yourself later, but for now let’s continue with the next technique !
Sparsifying
Now that we have a student model that is performing better than our baseline, we have some room to compress it. And we’ll start by making the network sparse. As explained in a previous article, there are many ways leading to a sparse network.
Note
Usually, the process of making a network sparse is called Pruning. I prefer using the term Pruning when parameters are actually removed from the network, which we will do in the next section.
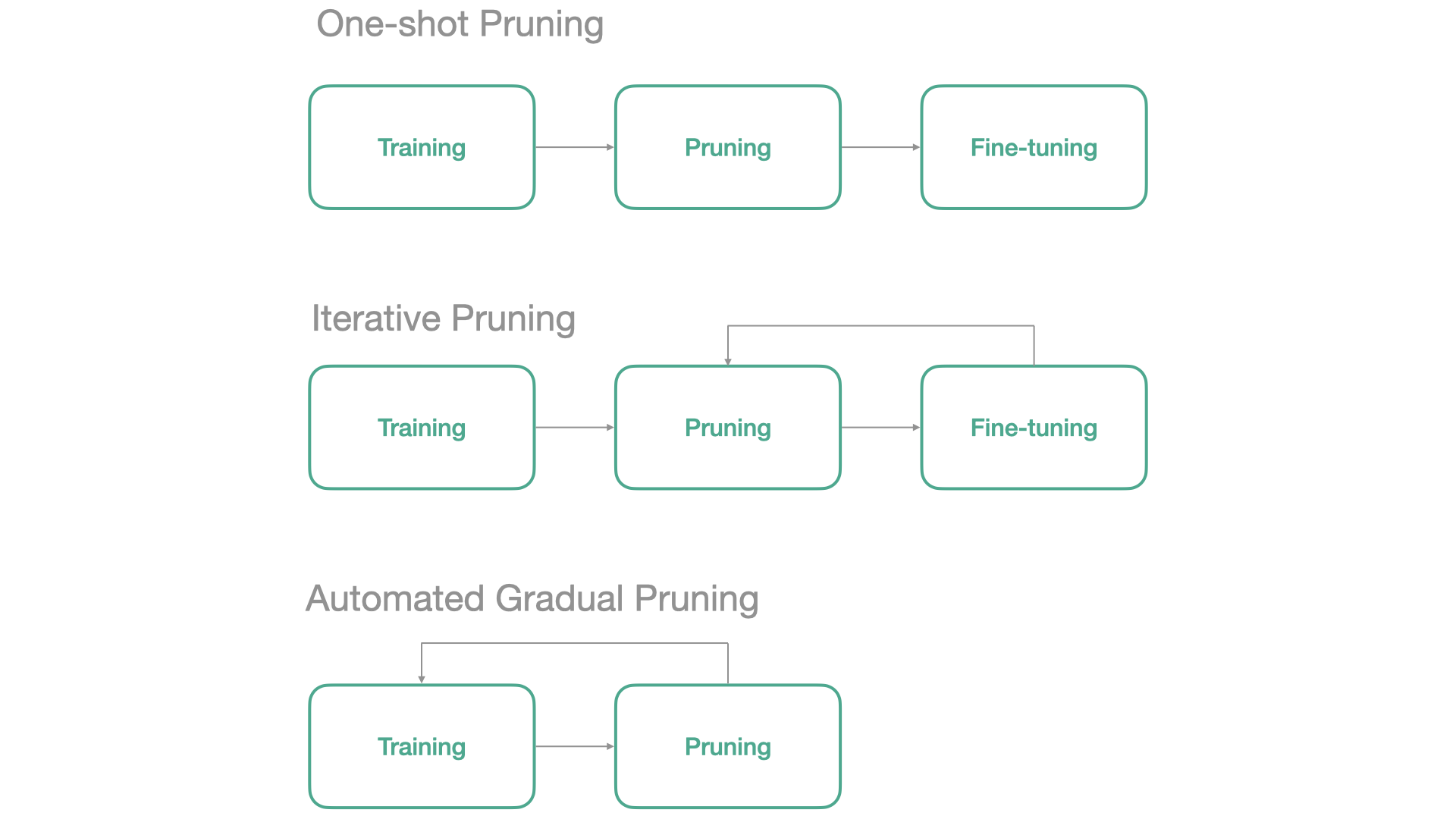
By default, FasterAI uses the Automated Gradual Pruning paradigm as it removes parameters as the model trains and doesn’t require to pretrain the model, so it is usually much faster. In FasterAI, this is also managed by using a callback, that will replace the least important parameters of your model by zeroes during the training. The callback has a wide variety of parameters to tune your Sparsifying operation, let’s take a look at them:
SparsifyCallback(learn, sparsity, granularity, context, criteria, schedule)
- sparsity: the percentage of sparsity that you want in your network
- granularity: on what granularity you want the sparsification to be operated
- context: either
localorglobal, will affect the selection of parameters to be choosen in each layer independently (local) or on the whole network (global).- criteria: the criteria used to select which parameters to remove (currently supported:
l1,taylor)- schedule: which schedule you want to follow for the sparsification (currently supported: any scheduling function of fastai, i.e
linear,cosine, … andgradual, common schedules such as One-Shot, Iterative or Automated Gradual)
But let’s come back to our example!
Here, we will make our network 40% sparse, and remove entire filters, selected locally and based on L1 norm. We will train with a learning rate a bit smaller to be gentle with our network because it has already been trained. The scheduling selected is cosinusoidal, so the pruning starts and ends quite slowly.
sp_cb = SparsifyCallback(sparsity=50, granularity='filter', context='global', criteria=large_final, schedule=cos)
student.fit(10, 1e-5, cbs=sp_cb)Pruning of filter until a sparsity of [50]%
Saving Weights at epoch 0| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.580802 | 0.602479 | 0.808917 | 00:24 |
| 1 | 0.608323 | 0.592913 | 0.807643 | 00:24 |
| 2 | 0.575951 | 0.594700 | 0.811210 | 00:24 |
| 3 | 0.569944 | 0.589884 | 0.815541 | 00:24 |
| 4 | 0.589329 | 0.572137 | 0.815796 | 00:24 |
| 5 | 0.586437 | 0.579539 | 0.813503 | 00:24 |
| 6 | 0.614333 | 0.627116 | 0.799236 | 00:24 |
| 7 | 0.628266 | 0.629826 | 0.796943 | 00:24 |
| 8 | 0.673765 | 0.646662 | 0.785478 | 00:24 |
| 9 | 0.645206 | 0.589828 | 0.809172 | 00:24 |
Sparsity at the end of epoch 0: [1.22]%
Sparsity at the end of epoch 1: [4.77]%
Sparsity at the end of epoch 2: [10.31]%
Sparsity at the end of epoch 3: [17.27]%
Sparsity at the end of epoch 4: [25.0]%
Sparsity at the end of epoch 5: [32.73]%
Sparsity at the end of epoch 6: [39.69]%
Sparsity at the end of epoch 7: [45.23]%
Sparsity at the end of epoch 8: [48.78]%
Sparsity at the end of epoch 9: [50.0]%
Final Sparsity: [50.0]%
Sparsity in Conv2d 2: 0.00%
Sparsity in Conv2d 5: 0.00%
Sparsity in Conv2d 9: 0.00%
Sparsity in Conv2d 12: 0.00%
Sparsity in Conv2d 16: 0.00%
Sparsity in Conv2d 19: 0.00%
Sparsity in Conv2d 22: 0.00%
Sparsity in Conv2d 26: 62.30%
Sparsity in Conv2d 29: 70.51%
Sparsity in Conv2d 32: 72.07%
Sparsity in Conv2d 36: 71.29%
Sparsity in Conv2d 39: 69.92%
Sparsity in Conv2d 42: 66.41%Our network now has 50% of its filters composed entirely of zeroes, without even losing accuracy. Obviously, choosing a higher sparsity makes it more difficult for the network to keep a similar accuracy. Other parameters can also widely change the behaviour of our sparsification process. For example choosing a more fine-grained sparsity usually leads to better results but is then more difficult to take advantage of in terms of speed.
Let’s now see how much we gained in terms of speed. Because we removed 50% of convolution filters, we should expect crazy speed-up right ?
print(f'Inference Speed: {evaluate_cpu_speed(student.model, x[0][None])[0]:.2f}ms')Inference Speed: 26.93msWell actually, no. We didn’t remove any parameters, we just replaced some by zeroes, remember? The amount of parameters is still the same:
num_parameters = get_num_parameters(student.model)
disk_size = get_model_size(student.model)
print(f"Model Size: {disk_size / 1e6:.2f} MB (disk), {num_parameters} parameters")Model Size: 537.31 MB (disk), 134309962 parametersWhich leads us to the next section.
Pruning
Why don’t we see any acceleration even though we removed half of the parameters? That’s because natively, our GPU does not know that our matrices are sparse and thus isn’t able to accelerate the computation. The easiest work around, is to physically remove the parameters we zeroed-out. But this operation requires to change the architecture of the network.
This pruning only works if we remove entire filters as it is the only case where we can change the architecture accordingly. Hopefully, sparse computations will soon be available on common deep learning librairies so this section will become useless in the future.
Here is what it looks like with fasterai:
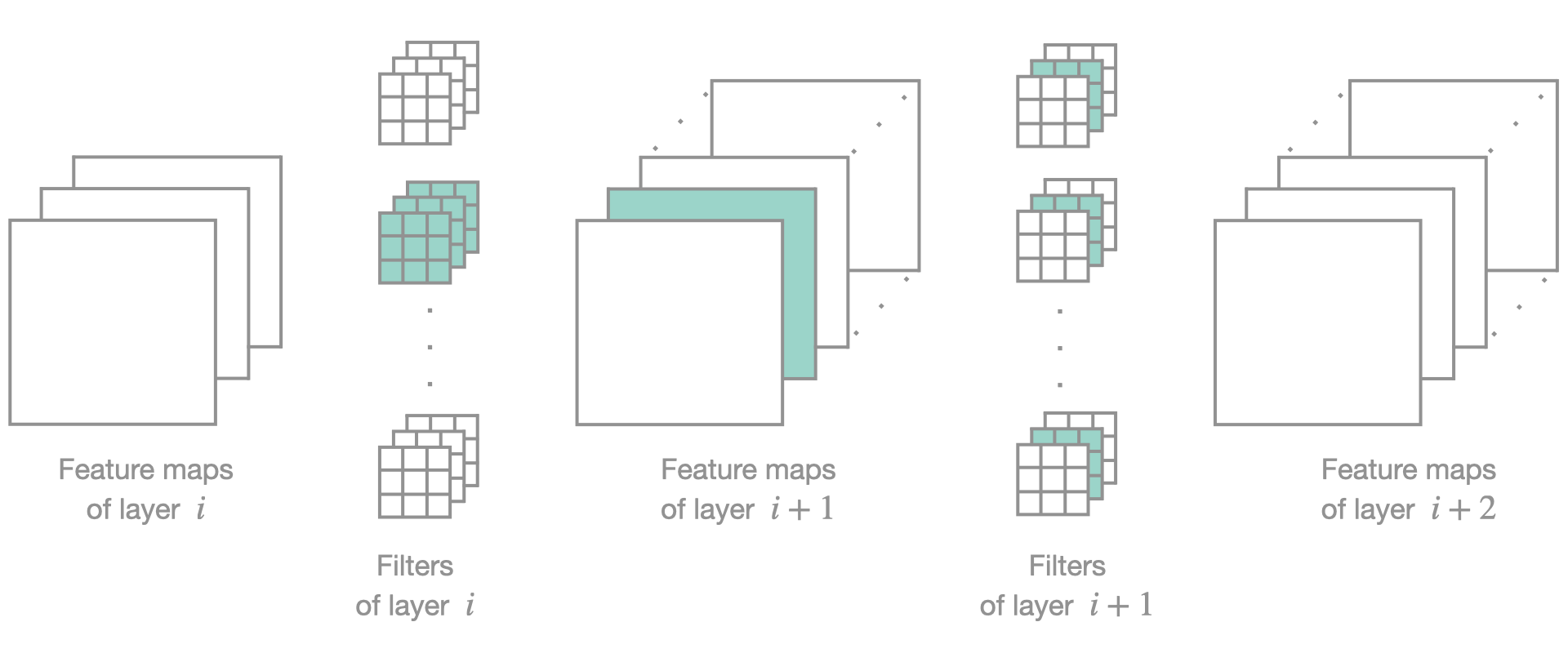
PruneCallback(learn, sparsity, context, criteria, schedule)
- sparsity: the percentage of sparsity that you want in your network
- context: either
localorglobal, will affect the selection of parameters to be choosen in each layer independently (local) or on the whole network (global).- criteria: the criteria used to select which parameters to remove (currently supported:
l1,taylor)- schedule: which schedule you want to follow for the sparsification (currently supported: any scheduling function of fastai, i.e
linear,cosine, … andgradual, common schedules such as One-Shot, Iterative or Automated Gradual)
So in the case of our example, it gives:
from fasterai.prune.all import *Let’s now see what our model is capable of now:
pr_cb = PruneCallback(sparsity=50, context='global', criteria=large_final, schedule=cos, layer_type=[nn.Conv2d])
student.fit(5, 1e-5, cbs=pr_cb)Pruning until a sparsity of [50]%| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.575356 | 0.585162 | 0.817070 | 01:21 |
| 1 | 0.596313 | 0.580011 | 0.815541 | 00:57 |
| 2 | 0.572922 | 0.581003 | 0.815287 | 00:46 |
| 3 | 0.565360 | 0.581362 | 0.815032 | 00:44 |
| 4 | 0.573613 | 0.574642 | 0.817834 | 00:44 |
Sparsity at the end of epoch 0: [4.77]%
Sparsity at the end of epoch 1: [17.27]%
Sparsity at the end of epoch 2: [32.73]%
Sparsity at the end of epoch 3: [45.23]%
Sparsity at the end of epoch 4: [50.0]%
Final Sparsity: [50.0]%num_parameters = get_num_parameters(student.model)
disk_size = get_model_size(student.model)
print(f"Model Size: {disk_size / 1e6:.2f} MB (disk), {num_parameters} parameters")Model Size: 218.53 MB (disk), 54620757 parametersAnd in terms of speed:
print(f'Inference Speed: {evaluate_cpu_speed(student.model, x[0][None])[0]:.2f}ms')Inference Speed: 16.41msYay ! Now we can talk ! Let’s just double check that our accuracy is unchanged and that we didn’t mess up somewhere:
And there is actually more that we can do ! Let’s keep going !
Batch Normalization Folding
Batch Normalization Folding is a really easy to implement and straightforward idea. The gist is that batch normalization is nothing more than a normalization of the input data at each layer. Moreover, at inference time, the batch statistics used for this normalization are fixed. We can thus incorporate the normalization process directly in the convolution by changing its weights and completely remove the batch normalization layers, which is a gain both in terms of parameters and in terms of computations. For a more in-depth explaination, see this blog post.
This is how to use it with FasterAI:
bn_folder = BN_Folder() bn_folder.fold(learn.model))Again, you only need to pass your model and FasterAI takes care of the rest. For models built using the nn.Sequential, you don’t need to change anything. For others, if you want to see speedup and compression, you actually need to subclass your model to remove the batch norm from the parameters and from the
forwardmethod of your network.
Note
This operation should also be lossless as it redefines the convolution to take batch norm into account and is thus equivalent.
from fasterai.misc.bn_folding import *Let’s do this with our model !
bn_f = BN_Folder()
folded_model = bn_f.fold(student.model)The parameters drop is generally not that significant, especially in a network such as VGG where almost all parameters are contained in the FC layers but, hey, any gain is good to take.
num_parameters = get_num_parameters(folded_model)
disk_size = get_model_size(folded_model)
print(f"Model Size: {disk_size / 1e6:.2f} MB (disk), {num_parameters} parameters")Model Size: 218.48 MB (disk), 54616533 parametersNow that we removed the batch normalization layers, we should again see a speedup.
print(f'Inference Speed: {evaluate_cpu_speed(folded_model, x[0][None])[0]:.2f}ms')Inference Speed: 15.63msAgain, let’s double check that we didn’t mess up somewhere:
folded_learner = Learner(dls, folded_model, metrics=[accuracy])
folded_learner.validate()(#2) [0.5746386647224426,0.8175796270370483]And we’re still not done yet ! As we know for VGG16, most of the parameters are comprised in the fully-connected layers so there should be something that we can do about it, right ?
FC Layers Factorization
We can indeed, factorize our big fully-connected layers and replace them by an approximation of two smaller layers. The idea is to make an SVD decomposition of the weight matrix, which will express the original matrix in a product of 3 matrices: \(U \Sigma V^T\). With \(\Sigma\) being a diagonal matrix with non-negative values along its diagonal (the singular values). We then define a value \(k\) of singular values to keep and modify matrices \(U\) and \(V^T\) accordingly. The resulting will be an approximation of the initial matrix.
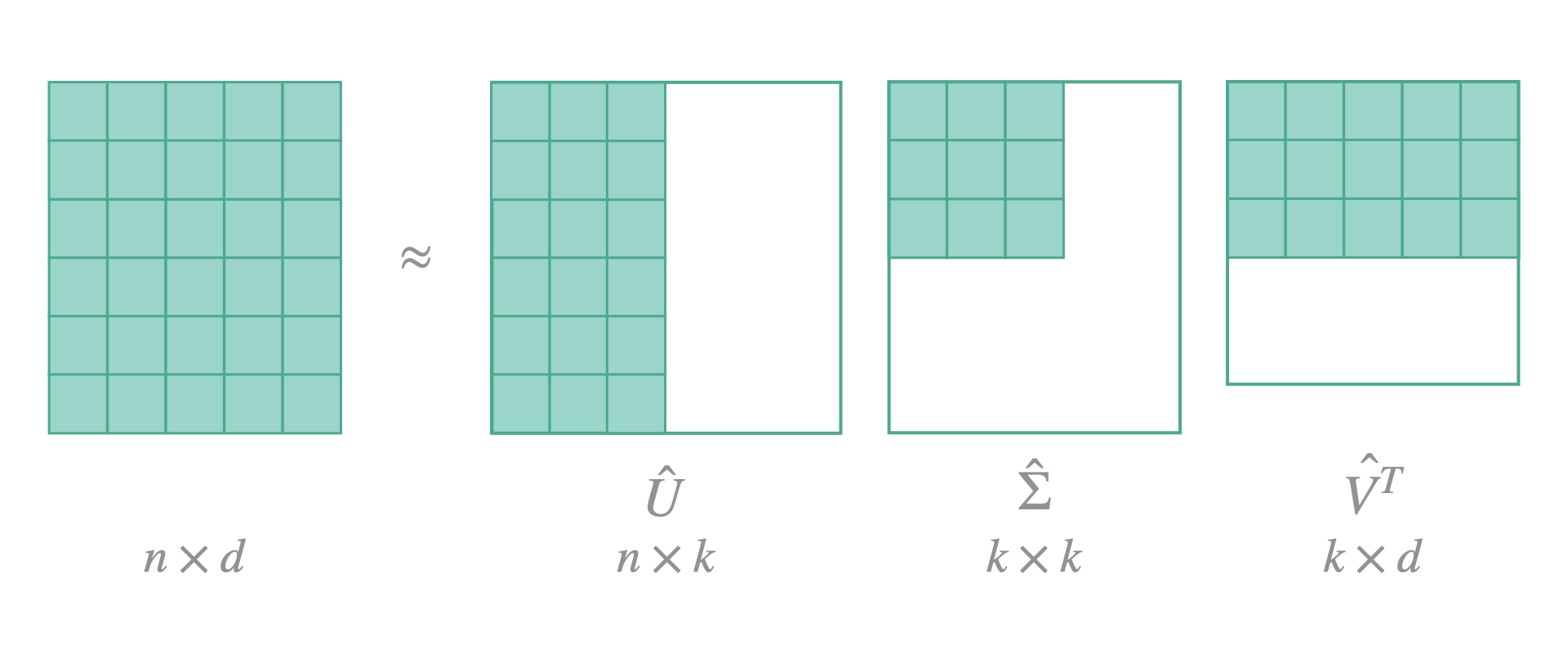
In FasterAI, to decompose the fully-connected layers of your model, here is what you need to do:
FCD = FCDecomposer() decomposed_model = FCD.decompose(model, percent_removed)The
percent_removedcorresponds to the percentage of singular values removed (k value above).
get_model_size(decomposed_model)182922786
Note
This time, the decomposition is not exact, so we expect a drop in performance afterwards and further retraining will be needed.
Which gives with our example, if we only want to keep half of them:
from fasterai.misc.fc_decomposer import *fc_decomposer = FC_Decomposer()
decomposed_model = fc_decomposer.decompose(folded_learner.model, percent_removed=0.5)How many parameters do we have now ?
num_parameters = get_num_parameters(decomposed_model)
disk_size = get_model_size(decomposed_model)
print(f"Model Size: {disk_size / 1e6:.2f} MB (disk), {num_parameters} parameters")Model Size: 182.91 MB (disk), 45724167 parametersAnd how much time did we gain ?
print(f'Inference Speed: {evaluate_cpu_speed(decomposed_model, x[0][None])[0]:.2f}ms')Inference Speed: 14.90msWe actually get a network that is a little bit slower, but at the expense of reducing the by 10M the number of parameter. This is thus a matter of compromise between network weight and speed.
However, this technique is an approximation so it is not lossless, so we should retrain our network a bit to recover its performance.
final_learner = Learner(dls, decomposed_model, metrics=[accuracy])
final_learner.fit_one_cycle(5, 1e-5)| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.738704 | 0.744383 | 0.756178 | 00:15 |
| 1 | 0.711042 | 0.769284 | 0.752102 | 00:15 |
| 2 | 0.695116 | 0.728815 | 0.755159 | 00:15 |
| 3 | 0.653428 | 0.732841 | 0.752357 | 00:15 |
| 4 | 0.609917 | 0.702751 | 0.762293 | 00:15 |
This operation is usually less useful for more recent architectures as they usually do not have that many parameters in their fully-connected layers.
Quantization
from fasterai.quantize.quantize_callback import *Now that we have removed every superfluous parameter that we could, we can still continue to compress our model. A common way to do so is now to reduce the precision of each parameter in the network, making it considerably smaller. Such an approach is called Quantization and won’t affect the total number of parameter but will make each one of them smaller to store, on top of making computations faster.
In FasterAI, quantization can be done in a static way, i.e. apply quantization to the model, also called Post-Training Quantization. It also can be applied dynamically during the training, also called Quantization-Aware Training.
final_learner.fit_one_cycle(5, 1e-5, cbs=QuantizeCallback())| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 0.672724 | 0.763105 | 0.742930 | 00:21 |
| 1 | 0.673187 | 0.831859 | 0.739108 | 00:21 |
| 2 | 0.649460 | 0.715663 | 0.762038 | 00:21 |
| 3 | 0.631277 | 0.690792 | 0.779873 | 00:21 |
| 4 | 0.557573 | 0.682759 | 0.796943 | 00:21 |
print(f'Inference Speed: {evaluate_cpu_speed(final_learner.model, x[0][None])[0]:.2f}ms')Inference Speed: 11.33msnum_parameters = count_parameters_quantized(final_learner.model)
disk_size = get_model_size(final_learner.model)
print(f"Model Size: {disk_size / 1e6:.2f} MB (disk), {num_parameters:,} parameters")Model Size: 46.02 MB (disk), 45,724,167 parametersExtra Acceleration
from fasterai.misc.cpu_optimizer import accelerate_model_for_cpufinal_model = accelerate_model_for_cpu(final_learner.model, x[0][None])print(f'Inference Speed: {evaluate_cpu_speed(final_model, x[0][None])[0]:.2f}ms')Inference Speed: 9.97msnum_parameters = get_num_parameters(final_model)
disk_size = get_model_size(final_model)
print(f"Model Size: {disk_size / 1e6:.2f} MB (disk), {num_parameters:,} parameters")Model Size: 46.02 MB (disk), 0 parametersSo to recap, we saw in this article how to use fasterai to:
1. Make a student model learn from a teacher model (Knowledge Distillation)
2. Make our network sparse (Sparsifying)
3. Optionnaly physically remove the zero-filters (Pruning)
4. Remove the batch norm layers (Batch Normalization Folding)
5. Approximate our big fully-connected layers by smaller ones (Fully-Connected Layers Factorization)
6. Quantize the model to reduce the precision of the weights (Quantization)
7. Extra acceleration techniques to further optimize the speed of our network
And we saw that by applying those, we could reduce our VGG16 model from 537 MB of parameters down to 46 MB (11x compression), and also speed-up the inference from 26.3ms to 9.9ms (2.6x speed-up) without any drop in accuracy compared to the baseline.
Note
Please keep in mind that the techniques presented above are not magic 🧙♂️, so do not expect to see a 200% speedup and compression everytime. What you can achieve highly depend on the architecture that you are using (some are already speed/parameter efficient by design) or the task it is doing (some datasets are so easy that you can remove almost all your network without seeing a drop in performance)